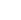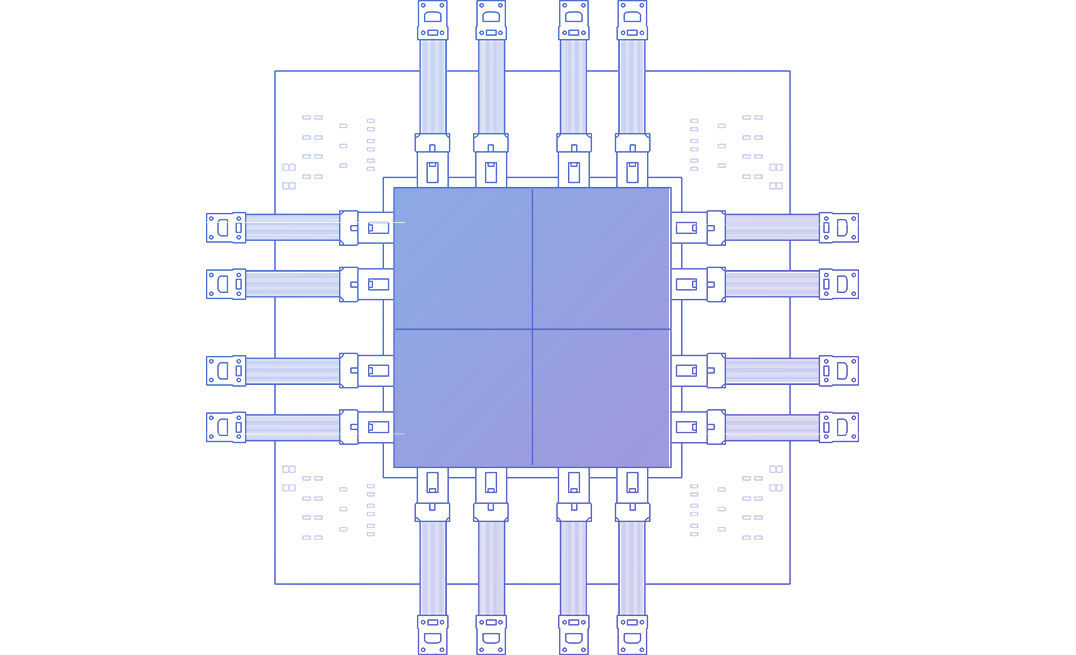

奇点光子采用芯粒级光 I/O 技术路线,将互连能力模块化,并前移至更靠近计算核心的位置。
通过缩短电路径并支持多样化封装集成,实现可扩展、低时延、低功耗的 AI 系统互连。



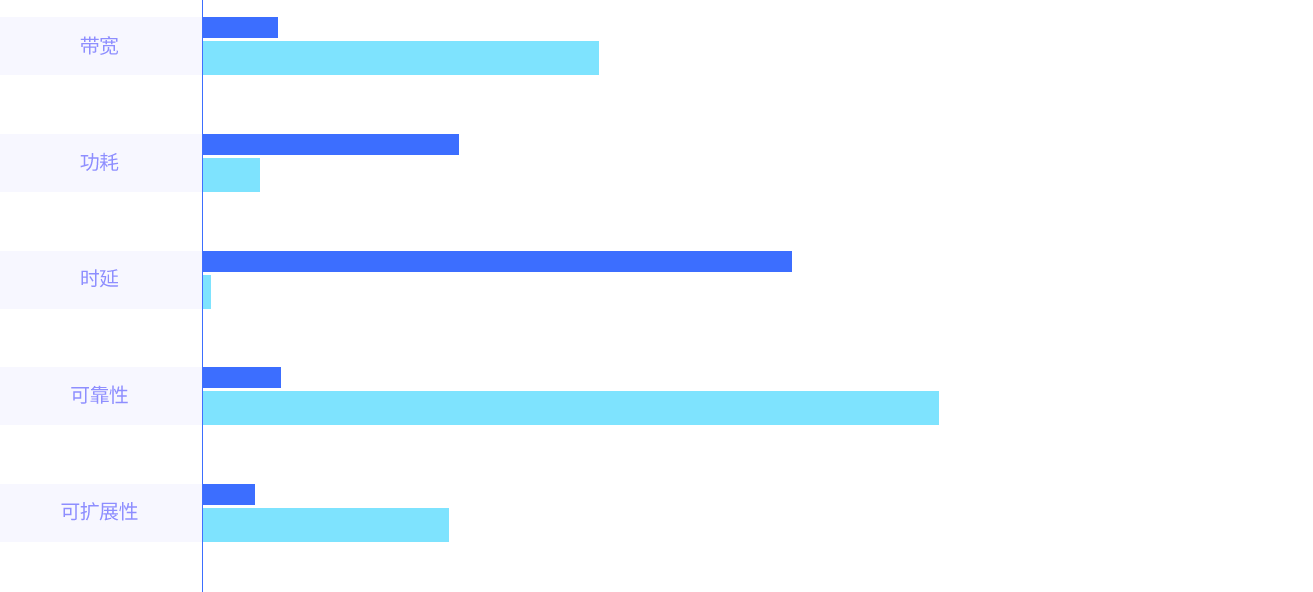
通过芯粒化光 I/O 与光电协同设计,在带宽密度、功耗、时延及系统可靠性等关键维度实现量级跃迁,为 AI 计算系统提供更高效、更稳定、更具扩展性的互连基础。